Bloom filters
Dec 28, 2013As promised in my previous post, I spent some time today understanding Bloom filters. While the wiki page intimidated me a bit when I first looked at it, it’s actually pretty simple once you sit down and patiently read through the whole thing.
- Bloom filters are a lot like hash maps, except that they save a lot on the space occupied for maintaining an index of your data at the cost of a minor chance of false positives.
- For a data set containing
nelements, if you have the ability to devotembits of memory to maintaining the bloom filter, you will needkdifferent hash functions that hash each of the elements in your data set with a uniform random distribution. - To add an element to the filter, hash that element with each of the
khash functions to getkarray positions in your map of sizem. Set the bits at all of these positions to 1. - To check if an element is present in your map (and hence in your data set), feed it to each of the
khash functions to getkarray positions. If any of the bits at thesekpositions are 0, then the element is definitely not in the set. If all are 1, then the element is either in the set, or you have a false positive.
See, pretty simple.
For a given m and n, the value of k that minimizes the probability of a false positive is

and the relationship between the length of the bloom filter m, the number of elements in the data set n and the probability of false positives p is given by
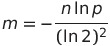
Figure 1: Bloom filter equation
Now, the reason I set out to learn about bloom filters is because I came across a couple of blog posts on Hackers News about using them to implement search on static websites, such as those generated by Jekyll. Search on dynamic sites is usually implemented as a server-side feature, where the client javascript sends the search query to the server, which then quickly searches in the content of all the webpages it serves and returns the list of results to the client. Since this is not possible in static websites, there’s only one option for implementing search: do it clientside. Now one could simply brute-force this by sending the entire site over to the client and then searching through it in Javascript, but that’s the stupid way of doing it. The more elegant way is to send as little data to the client as possible, only enough for the client to determine which pages have the results of the search query, and then to show those pages as the search results. And given the space-efficiency of bloom filters, they appear to be a natural fit for this problem.
I’m not sure what the ideal way of using bloom filters would be for implementing a site-wide search, but the best implementation I’ve come up with is to create one filter per page and then to send those filters to the client and have the client look up the search query in each filter. I’m sure there are more efficient ways of doing this, but just for fun I’m going to do it my way first, and then look at other solutions only if I’m not happy with mine.
So, time to learn some ruby.